What Is a Forward Deployed Engineer? My Experience With the Model
- •
- 10 min
- •
- RSS
Forward Deployed Engineer · Dubai
The term exists in a few different forms.
There's the Palantir version — engineers embedded at government and defense clients, working inside data infrastructure that standard IT contracts can't reach. At one point, Palantir employed more forward deployed engineers than traditional software engineers — the model wasn't a support tier built around the product, it was how the product got deployed.
There's the OpenAI version — $265,000 roles deploying AI systems at enterprises, backed by a $4 billion deployment company launched last year. And then there's the version that's proliferating everywhere else in 2026: someone technical who goes into a client environment, figures out what's actually broken, and builds something that fixes it.
The third one is the definition that matters to most organizations looking at this model. And it's the hardest one to explain, because it sounds like consulting, or contracting, or some combination of both.
It's not quite either.
I came to the term late. I'd been doing this kind of work for years before finding the label — sitting at client desks, watching how the work actually moved, building systems designed to run without me once the engagement ended. When I finally saw "Forward Deployed Engineer" in a job posting, the description was instantly recognizable. The name was new. The pattern wasn't.
Reading about the role — Marty Cagan at SVPG, The New Stack on the OpenAI and Google hiring race — sent me back through my own project history. What follows is what the model looks like from inside the client engagements, not a definition of it.
What makes it different from consulting
A consultant analyzes a problem and delivers a recommendation. The output is a document — sometimes a slide deck, sometimes a detailed implementation plan. The quality of that output is measured by how clearly it describes the problem and how specific the recommendations are.
A Forward Deployed Engineer delivers a working system. Not a recommendation for one. The system itself, running in production. The engagement ends when the thing is deployed and working, not when the analysis is complete.
That's a real distinction, not a positioning one. A consultant can do their best work without writing a line of code. An FDE's engagement ends when the system is in production, not when the analysis is finished.
The accountability structure is different too. Consultants are often incentivized — not deliberately, just structurally — to surface complexity that justifies ongoing engagement. An FDE's whole model depends on building something that runs without them. The faster and more completely they can achieve that, the better they look. Those incentives point in opposite directions.
What makes it different from contracting
A contractor takes a specification and returns code. The spec is a precondition for the work: you give me the requirements, I give you the implementation.
A Forward Deployed Engineer enters the environment before a specification exists. The discovery — figuring out what to actually build — is part of the engagement, not something that happens before it starts.
This matters because the spec is usually wrong.
Not through anyone's fault. Requirements documents describe processes the way people think they work, not the way they actually work. The difference between those two things is often where the real problem lives — and it's only visible from inside the operational environment.
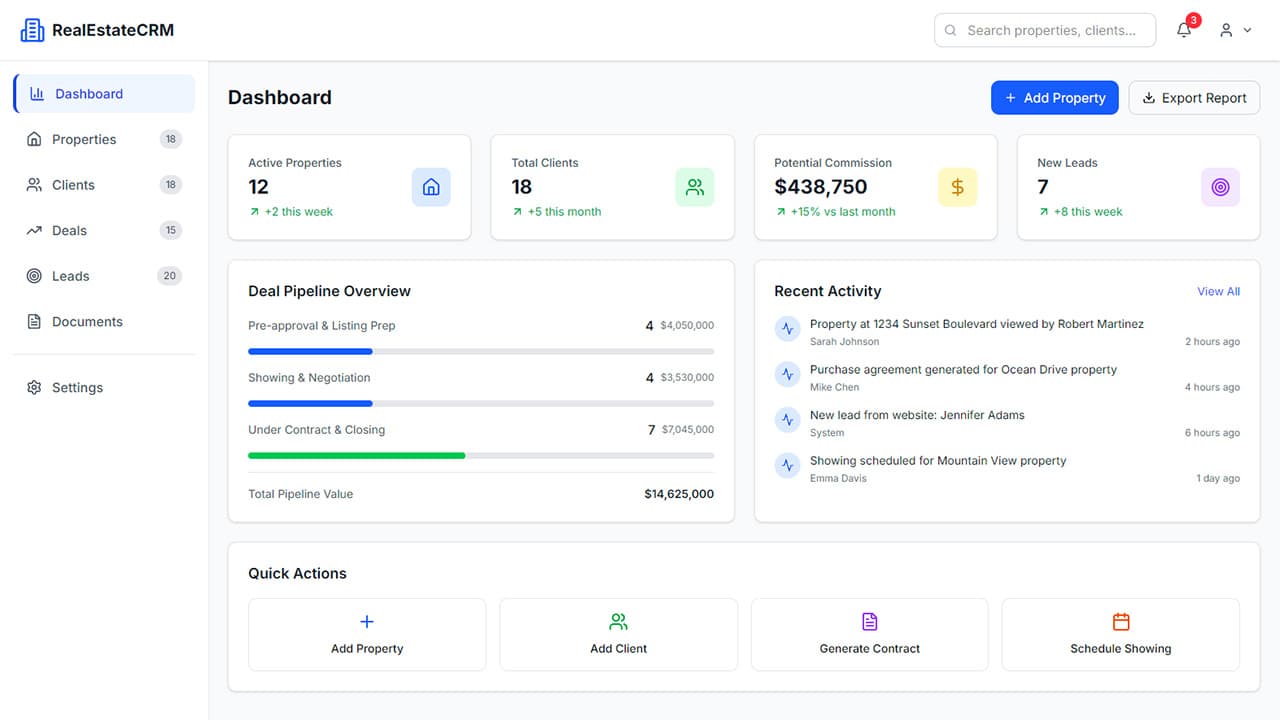
For RealEstateCRM, I spent time in the client's office watching how agents actually moved listings and leads through their pipeline before writing a line of code. The stated problem was listings management — too many properties scattered across too many places. The actual problem, which only became visible by watching agents work for a few days, was the client pipeline.
Agents were losing track of where each client was in the buying process, not where each property was. Those are different systems. A contractor starting from the stated spec would have built the wrong one. The right system came from being inside the environment long enough to see what the work actually looked like.
Put plainly:
| Role | Discovers | Builds | Accountable for outcome |
|---|---|---|---|
| Consultant | ✓ | ||
| Contractor | ✓ | ||
| Forward Deployed Engineer | ✓ | ✓ | ✓ |
What the discovery actually looks like
The discovery phase is not interviews. Not a requirements workshop. Not a survey of stakeholders.
It's observation — specifically, watching the operational reality: how work flows through a team, where it gets stuck, where it gets duplicated, where tribal knowledge substitutes for a system that doesn't exist yet.
With Automator, the stated problem was "we spend too much time publishing." Once I actually mapped the workflow:
- Download files from source location
- Rename according to a specific naming convention
- Organize into dated folders
- Archive the originals
- Upload to three different sites in a specific order
- Post across several more platforms
Seventeen distinct steps, four hours of work. Each one a potential failure point.
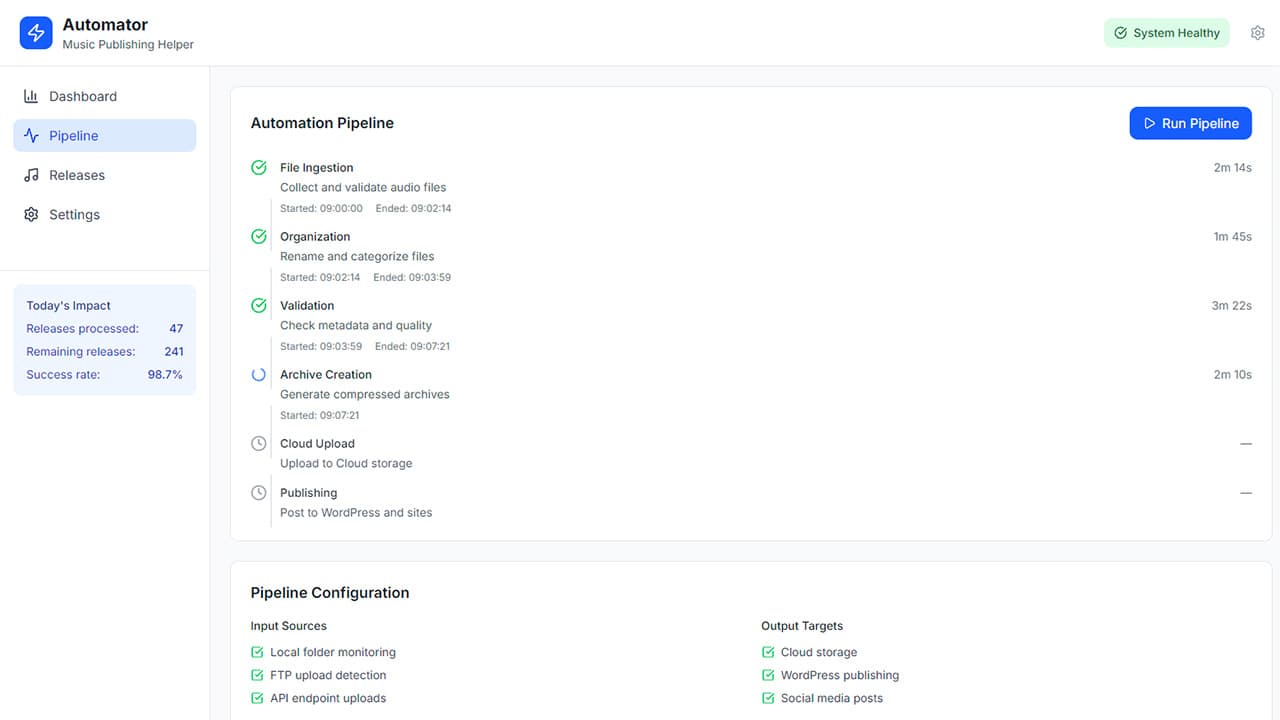
No spec would have captured all seventeen — not because the client was hiding anything, but because they had been doing it so long they'd stopped seeing the individual steps. They saw "publishing." It took watching the process to see seventeen separate failure points.
The system I built replaced the seventeen steps with a single review that takes fifteen minutes. It has published 200,000+ music releases since 2021. The client runs it daily with no involvement from me.
That outcome wasn't available through requirements gathering. It required being inside the operational reality long enough to understand what was actually happening.
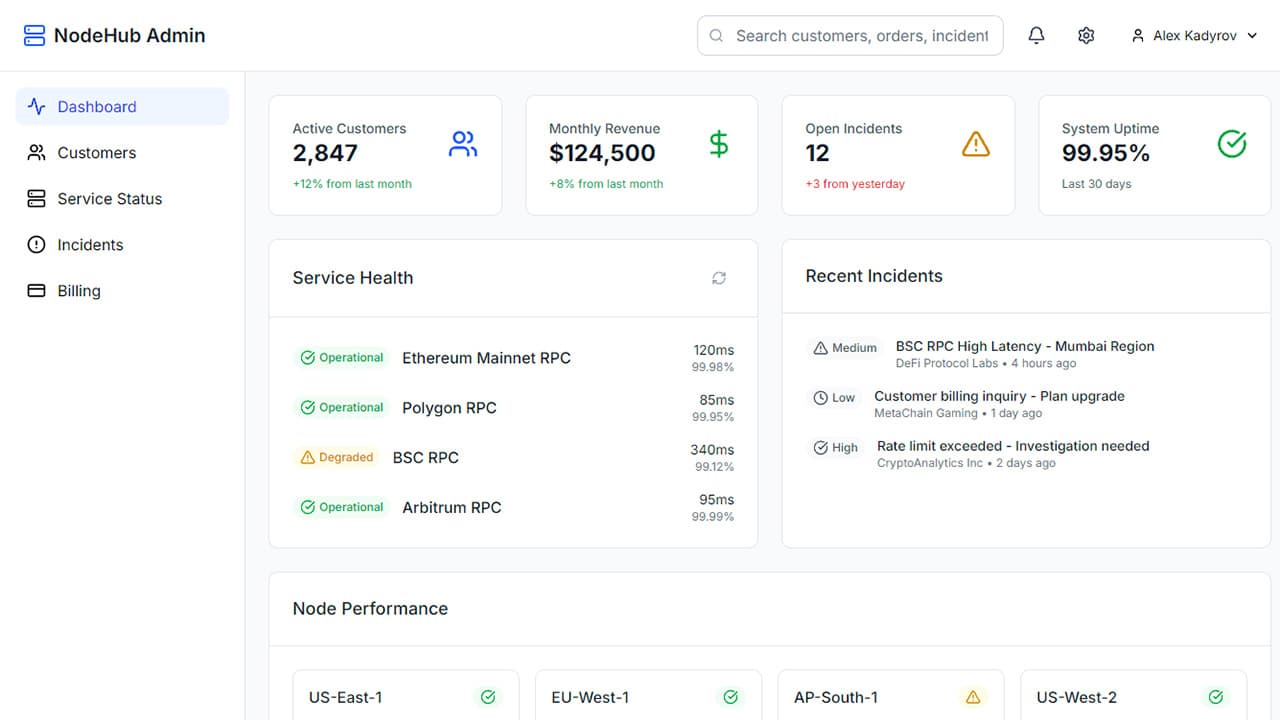
The type of discovery varies. With Admin Manager Panel, a support team described slow ticket resolution — the kind of complaint that sounds like a process problem. Watching agents work for a day made the actual problem visible: they were switching between three to five separate systems for every ticket — customer data in one place, service status in another, billing in a third. No individual system was broken.
The friction was the switching between them. A single dashboard that surfaced the right context for each ticket cut resolution time by around 70%. Nothing in the underlying tools changed. The integration layer between them was what was missing.
The handoff is the goal from day one
This is the part most descriptions underemphasize.
The engagement model only works — financially, logistically, practically — if the system runs without the engineer after the engagement ends. An FDE who builds something that requires their ongoing presence hasn't completed the job. They've created a dependency.
Everything I build is designed to run without me. Not as an aspiration — as a design constraint.
That means:
- Documentation covers every non-obvious decision
- Handoff includes training for whoever operates the system, and the architecture carries no hidden dependencies on my knowledge or access
RealEstateCRM has run since 2021 without a single support call. Automator the same. Those aren't just performance metrics for the products — they're the performance metric for the engagements. If those systems needed me, the engagements would have failed on the most important criterion, regardless of how well the software worked.
FutureAngel — LP onboarding, KYC/AML checks, deal tracking, and fund reporting — is a different version of the same story. The system is live. The handoff happened. But my collaborator and I stepped back not because the engagement was technically complete in the usual sense, but because we recognized mid-build that VC fund management has real domain depth: regulatory edge cases, LP relationship dynamics, compliance requirements that keep evolving. Sustaining the system at the level the design partners needed required someone who lived in that world permanently. We handed it to people who did. The product still runs. That's still a clean handoff — it just meant being honest about where embedded engineering stops and deep domain ownership takes over.
Why this model is expanding
The immediate explanation is enterprise AI deployment.
Large organizations are integrating AI into their operations and discovering that the distance between "the model can do this" and "our operations actually run on this" is substantial. Around 95% of enterprise AI projects fail to deliver measurable return on investment — not because the models don't work. The models work. The API exists. But reaching production requires someone who can embed inside the organization's workflows, understand why the first two integrations didn't hold, and build the version that does.
That requires an engineer who can diagnose and build inside the environment — not an advisor who can describe what should happen, and not a contractor who can implement a spec that someone else discovered. The FDE model is expanding because enterprise AI deployment is the exact problem it's designed for.
The number of FDE roles globally grew 42× between 2023 and 2025, according to LinkedIn's January 2026 labour market report. OpenAI's deployment company didn't describe itself as a consulting practice — it described itself as an engineering practice accountable for production outcomes. That framing matters to the clients: they don't want a plan for how AI could help. They want running AI systems.
But enterprise AI is just the loudest current version of a recurring problem. The model — embedded engineer, discovery inside the environment, outcome accountability, clean handoff — applies anywhere a software solution has to fit inside an existing operational reality rather than replace it wholesale:
- Real estate agencies managing 200+ listings in Excel
- Music publishers with four-hour daily routines
- Support teams switching between five tools to handle a single ticket
- Investment funds onboarding LPs through email chains
None of these organizations need a SaaS product. They need someone who will get inside how they actually work, understand what's broken, and build the specific thing that fixes it.
That's what the engagement model produces. A working system, built to run without you, delivered from inside the problem.
When this model doesn't fit
If you already know exactly what needs to be built, hire a contractor. The spec exists, the requirements are solid, you need execution — FDE work would just add unnecessary discovery overhead. The embedded process exists specifically for situations where the right spec requires being inside the environment to write.
And if the real question is whether the thing is worth building at all, that isn't an FDE engagement either — that's an MVP question, and it starts from the opposite premise. The FDE model assumes the problem is already real and the customer already exists; the market question is settled before the engagement begins.
The engagement also depends on one specific thing being true on the client side: someone has to exist who will own the system after delivery. Not just users — someone who understands how it works, will learn to operate it, and will catch it when something breaks. A clean handoff requires somewhere to land. If there's no internal person in that role, the system will decay on its own timetable regardless of how well it was built. That's not a flaw in the model; it's a precondition the model requires.
Finally: the problem has to be real and operational, not theoretical. "We should probably automate X someday" and "we spend four hours every morning on X and it breaks two or three times a week" are different conversations. The discovery process works because there's actual work to observe — a real workflow with real friction, visible failure points, people with workarounds baked into their muscle memory. A theoretical problem doesn't have that. It has assumptions about what will be hard once someone eventually builds the workflow, which is a different engagement entirely.
Working with a forward deployed engineer in Dubai
I'm based in the UAE, and most of the embedded work described above now happens with Dubai and wider GCC teams — a brokerage, a founder a few months past product-market fit, a small operations team carrying a critical process in spreadsheets and tribal knowledge.
The model fits this market for a specific reason. Dubai runs on small, fast-moving teams that have outgrown the tools they started on: a real estate agency tracking 200+ listings in Excel, a publisher with a four-hour daily routine, a support desk hopping between five systems to close one ticket. None of them needs a SaaS subscription or a six-month consulting deck. They need someone who will sit inside the operation, see what is actually breaking, and hand back a system that runs without them.
If you're looking to hire a forward deployed engineer — or a forward deployed developer; the title varies more than the work does — in Dubai or the UAE, the one thing worth checking is whether the engagement is structured around a clean handoff or around staying. How I structure the work is on the service page: discovery first, inside your environment; a defined scope once the real problem is visible; and a system documented well enough that your own team owns it after I step back.
I take on embedded delivery engagements as a Forward Deployed Engineer — discovery first, defined scope, clean handoff. See how the engagement works or book a discovery call if there's an operational problem that software should have fixed already.